Databse Design for Software Engineer (Part 1)
If you see a diagram that looks like this but you have vague understanding of the ERD, then it is a good idea to read this blog and understand what does this actually means and also how to design your database effectively.
Today's Agendas
- Database, RDBMS
- Database Design, Data Integrity
- Design Objectives
- Terminology
- Establishing Table structure
- Database design principles
- Database design patterns
- Normalization, denormalization, sharding, and partitioning
- Fields, Indexes, Constraints, Relationships, Keys, Triggers
- Understanding Entitiy Relationship Diagram (ERD)
- Bad Design Practices
Database, RDBMS
I am not going through, what is database and what is RDBMS. I am assuming that you might have already know the theorital definition of database, and have some knowledge of it already.
Database Design and Data Integrity
Database Design is the process of structuring a database in a way that meets
the needs of an organization, ensuring data is stored, managed, and retrieved
efficiently. Good database design is essential for building applications that
are scalable, maintainable, and performant. The design process involves defining
the database schema, which includes tables, fields, relationships, constraints,
and indexes.
Key principles of database design include:
- Normal Forms ( Normalization)
- Data Integrity
- Entity-Relationship Modeling
- Scalability
- Performance Optimization and Reliability
- Security and Privacy
Data Integrity refers to the accuracy, consistency, and reliability of data
throughout its lifecycle. It ensures that the data stored in a database is
accurate and unaltered during operations like insertion, update, or deletion.
Maintaining data integrity is crucial for ensuring that the data in a database
remains trustworthy and meaningful, supporting accurate decision-making and
business operations.
Ensuring the accuracy and consistency of data through the use of primary keys, foreign keys, and constraints (e.g., NOT NULL, UNIQUE, CHECK).
Entity Integrity: Ensures that each record in a database table is uniquely
identifiable. This is often achieved through primary keys, where each entry has
a unique identifier.
- Example: In a User table, UserID serves as a primary key ensuring no two users have the same ID.
Referential Integrity: Ensures that relationships between tables remain
consistent. Foreign keys are used to enforce referential integrity, ensuring
that a record in one table corresponds to a valid record in another table.
- Example: If an Orders table references a CustomerID from a Customers table, referential integrity ensures that each CustomerID in the Orders table matches a valid CustomerID in the Customers table.
Domain Integrity: Ensures that all data in a database field is valid according
to predefined rules, such as data types, formats, and ranges.
- Example: A BirthDate field should only contain valid dates and not allow values like '2024-13-45'.
User-Defined Integrity: Custom rules that enforce specific business logic
constraints, which might not be covered by the other three types of integrity.
Example: A rule that ensures an OrderTotal must always be greater than zero.
Design Objectives
Design Objectives are the goals and criteria that guide the process of
creating effective and efficient systems, products, or structures. In the
context of software development and database design, these objectives ensure
that the final product meets user needs, performs well, and is maintainable over
time. Achieving these objectives involves balancing functionality, usability,
performance, and security.
Flexibility, Reliability, maintainability, Compatibility, Usability, Functionality, and Scalability
are the key design objectives.
Terminology
Table, Relation, file
A table (also known as a database schema) is a collection of related data
records, and it is the fundamental unit of data storage in a database. It is
also known as a database schema.
Record, Row, Tuple
A record (also known as a database row) is a single row in a table, and it is the fundamental unit of data storage in a database.
Others
Value is information that is stored in a table or record. Entity/Object commonly refers to a Table. like User, Order, Product, etc.
SQL
Structured Query Language (also known as a database query language) is a programming language that is used to communicate with databases.
- DDL - Data Definition Language
- DML - Data Manipulation Language
- DCL - Data Control Language
- TCL - Transaction Control Language
SQL Keywords - you should not name your database table with SQL keywords. For
example, SELECT, FROM, WHERE, JOIN, INSERT is a SQL keyword.
Fields
A field (known as an attribute in relational database theory) is the smallest structure in the database, and it represents a characteristic of the subject of the table to which it belongs. Columns Atributes is also a field.
You'll typically encounter multiple types of fields in a database, or let's say in improperly or poorly designed database.
Multipart fields( also known as composite fields ), it contains two or more distinct items within its value. i.e. 4879 Diamond Cove, Providence, Rhode Island, 02903Multivalued fieldswhich contains multiple instances of the same type of value.Calculated fieldswhich contains a concatenated text value or the result of a mathematical expression.
Example of fields in user table
| id | name | dob | age | address | |
|---|---|---|---|---|---|
| 1 | John | [email protected] | 2001-01-01 | 20 | 4879 Diamond Cove, Providence, Rhode Island, 02903 |
| 2 | Doe | [email protected] | 2006-02-01 | 18 | 4879 Diamond Cove, Providence, Rhode Island, 02903, USA, USA |
| 3 | Jane | [email protected] | 1999-01-01 | 22 | 4879 Diamond Cove, Providence, Rhode Island, 02903, USA |
In the above table, you can see Multivalued fields, Multipart fields, and
Calculated fields errors.
Multivalued fields: The dob and age field has multiple instances of the same type of value.Multipart fields: The address field has multiple distinct items within its value.Calculated fields: The age field is calculated from the dob.
keys
In database design, keys are critical components that help ensure data integrity, uniqueness, and relationships between tables. They are used to uniquely identify records, enforce constraints, and establish links between tables. Understanding the different types of keys is essential for creating efficient and reliable database schemas.
Types of Keys
-
Primary Key: A unique identifier for each record in a table. It ensures that no two records have the same value in this key.
- Example:
UserIDin aUserstable.
- Example:
-
Surrogate Key: An artificial key assigned by the system, often a sequential number, that has no real-world meaning but is used as a primary key.
- Example: An auto-incrementing integer like
UserID.
- Example: An auto-incrementing integer like
-
Natural Key: A key that has a real-world meaning and is used as a primary key.
- Example: A
SocialSecurityNumberas a primary key.
- Example: A
-
Alternate Key: A candidate key that is not chosen as the primary key. It is a unique key but not the main identifier.
- Example: An email address in a
Userstable, whenUserIDis the primary key.
- Example: An email address in a
-
Super Key: A set of one or more columns that can uniquely identify a record. Every primary key is a super key, but not all super keys are primary keys.
- Example:
{UserID, Email}together can be a super key.
- Example:
-
Candidate Key: A minimal super key, meaning no subset of it can uniquely identify a record. All candidate keys are potential primary keys.
- Example:
UserIDorEmailalone can be a candidate key.
- Example:
-
Foreign Key: A key in one table that links to the primary key in another table, establishing a relationship between the two.
- Example:
OrderIDin anOrderstable that referencesUserIDin aUserstable.
- Example:
-
Not Null Key: A key that must always contain a value, ensuring that a field is never left blank.
- Example:
UserIDset asNOT NULL.
- Example:
-
Simple Key: A key that consists of a single column.
- Example:
UserID.
- Example:
-
Composite Key: A key that consists of two or more columns to uniquely identify a record.
- Example:
OrderIDandProductIDtogether as a composite key in anOrderDetailstable.
- Example:
-
Compound Key: Another term for a composite key, where multiple columns together form a unique identifier.
- Example:
{FirstName, LastName, BirthDate}as a compound key in aPersonstable.
- Example:
Relationship
-
One-to-One: A relationship between two tables where one table has a reference to another table.
-
One-to-Many: A relationship between two tables where one table has a reference to many tables.
-
Many-to-Many: A relationship between two tables where one table has a reference to many tables.
-
Many-to-One: A relationship between two tables where one table has a reference to many tables.
Understanding Entity Relationships Diagram
Cardinality and Modality
Cardinality refers to the number of instances of one entity that can be
associated with an instance of another entity. It defines the quantitative
aspect of the relationship between two entities. Minimums and maximums
Help define the relationship in a numerical context.
-
one to one: 1-1
-
one to many: 1-N
-
many to many: M-N
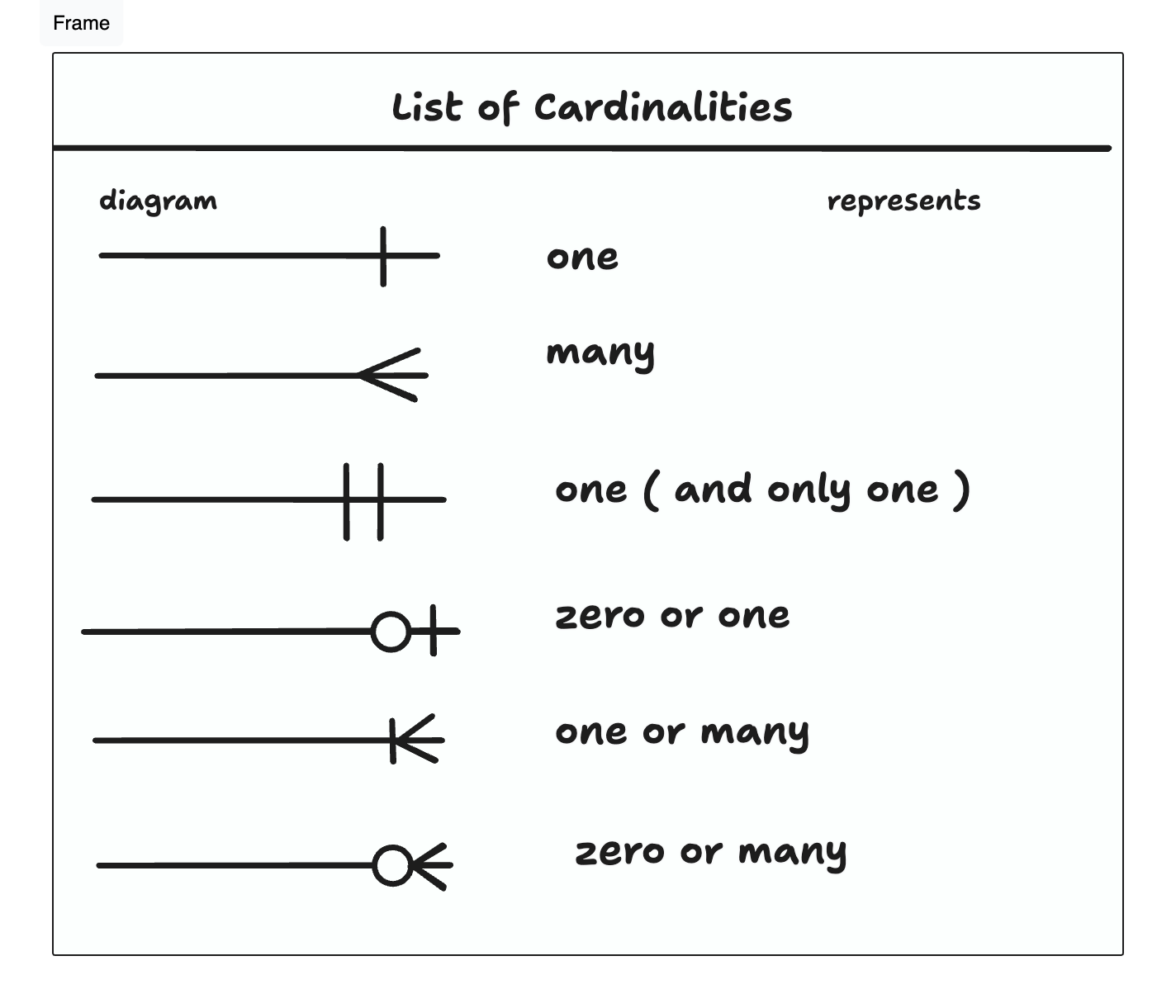
-
Minimums: The minimum number of instances that can be associated with an instance of another entity.
-
Maximums: The maximum number of instances that can be associated with an instance of another entity.
Modality (also known as optionality) refers to the minimum number of instances that must be involved in a relationship between entities. It defines whether participation in a relationship is mandatory or optional.
Indexes in Databases
Indexes in databases are data structures that improve the speed of data retrieval operations on a table. They work like a book's index, allowing the database to find rows quickly without scanning the entire table. There are different types of indexes, each suited for specific scenarios.
Think of an index as a bookshelf, or a phonebook with an index on the name.
Types of Indexes
1. Clustered Index
A clustered index determines the physical order of data in a table. There can be only one clustered index per table because the data rows themselves are stored in the index order. When a table has a clustered index, it’s called a clustered table.
-
Example: Consider a
Userstable whereUserIDis the primary key. If you create a clustered index onUserID, the rows in theUserstable will be physically stored in ascending order ofUserID.CREATE CLUSTERED INDEX idx_userid ON Users(UserID);
2. Non-Clustered Index
A non-clustered index does not alter the physical order of the data in the table. Instead, it creates a separate structure within the table that points to the data rows. You can have multiple non-clustered indexes on a single table.
-
Example: In the same
Userstable, if you frequently search byEmail, you can create a non-clustered index on theEmailcolumn.CREATE NONCLUSTERED INDEX idx_email ON Users(Email);
3. Composite Index
A composite index (or compound index) is an index on two or more columns
of a table. It is used when queries often involve multiple columns in the
WHERE clause or in joins.
-
Example: If you often query the
Userstable by bothLastNameandFirstName, you can create a composite index on these two columns.CREATE INDEX idx_name ON Users(LastName, FirstName);
Summary
- Clustered Index: Orders the physical data in the table and can only be one per table.
- Non-Clustered Index: Creates a separate structure for indexing without altering the data order; multiple non-clustered indexes can exist on a table.
- Composite Index: An index on multiple columns, useful for queries that filter by more than one column.
Normalization
Database normalization is a design process used to organize a database into tables and columns to reduce data redundancy and improve data integrity. The primary goals are to:
- Eliminate redundant data
- Reduce Inconsistencies: Prevent anomalies in data operations (insert, update, delete).
- Easier to understand
- Easier to ehnance and maintain
- Protected from insertion anomalies, deletion anomalies, and duplication anomalies
We have different types of normalization. 1NF, 2NF, 3NF, 4NF, 5NF
Ok, wth is it? you can think of it as a saftey level of a bridge, if we say 1NF it means it have the saftey level of 1. If we say 2NF it means it has the saftey level of 2. So on. Here in our case, if we say our database have the normalization level of 3NF it means it has the saftey level of 3. I hope you got the point if not we can go through examples to understand it.
Example Table: Normalization
Normalization is the process of organizing data in a database to reduce redundancy and improve data integrity. The process involves dividing a database into two or more tables and defining relationships between them. Below is an example of how a table might be normalized through the first three normal forms (1NF, 2NF, 3NF).
Unnormalized Table
Before normalization, let's consider an unnormalized table where data redundancy exists:
Orders Table
| OrderID | CustomerName | CustomerAddress | ProductName | Quantity | Price |
|---|---|---|---|---|---|
| 1 | John Doe | 123 Elm St, Springfield | Laptop | 1 | 1000 |
| 1 | John Doe | 123 Elm St, Springfield | Mouse | 2 | 25 |
| 2 | Jane Smith | 456 Oak St, Springfield | Laptop | 1 | 1000 |
| 2 | Jane Smith | 456 Oak St, Springfield | Keyboard | 1 | 50 |
First Normal Form (1NF)
In the First Normal Form, each column contains atomic (indivisible) values, and each entry in a column contains only one value. The table above already meets 1NF because all columns contain atomic values.
Second Normal Form (2NF)
In the Second Normal Form, the table must first meet 1NF, and all non-key attributes must be fully dependent on the primary key.
To achieve 2NF, we separate the Orders table into two tables: Customers and
OrderDetails.
Customers Table
| CustomerID | CustomerName | CustomerAddress |
|---|---|---|
| 1 | John Doe | 123 Elm St, Springfield |
| 2 | Jane Smith | 456 Oak St, Springfield |
OrderDetails Table
| OrderID | CustomerID | ProductName | Quantity | Price |
|---|---|---|---|---|
| 1 | 1 | Laptop | 1 | 1000 |
| 1 | 1 | Mouse | 2 | 25 |
| 2 | 2 | Laptop | 1 | 1000 |
| 2 | 2 | Keyboard | 1 | 50 |
Third Normal Form (3NF)
In the Third Normal Form, the table must be in 2NF, and all the columns must depend directly on the primary key. To achieve 3NF, any transitive dependency (where a non-key column depends on another non-key column) must be removed.
For this example, let's split the OrderDetails table further to avoid
redundancy in product information.
Products Table
| ProductID | ProductName | Price |
|---|---|---|
| 1 | Laptop | 1000 |
| 2 | Mouse | 25 |
| 3 | Keyboard | 50 |
OrderDetails Table (Revised)
| OrderID | CustomerID | ProductID | Quantity |
|---|---|---|---|
| 1 | 1 | 1 | 1 |
| 1 | 1 | 2 | 2 |
| 2 | 2 | 1 | 1 |
| 2 | 2 | 3 | 1 |
Summary of Normalization
- 1NF: Atomic values and no repeating groups.
- 2NF: No partial dependencies (all non-key columns depend on the whole primary key).
- 3NF: No transitive dependencies (non-key columns do not depend on other non-key columns).
By normalizing the tables, we have reduced redundancy and improved the integrity of the data in our database.
Conclusion
That's it for the first part of our database design series. We have learned how to normalize a database and how to design a database schema for a retail store. This is just the beginning of our journey into database design. In the next part, we will dive into more advanced topics and actually creating the example and making erd.
Stay tuned for the next part, which will be published soon. If you have any questions or feedback, please let me know in the comments below.